分布式缓存映射算法
传统hash取模
实现分布式系统的负载均衡, e.g. idx := ihash(kv.Key) % nReduce
node_number = hash(key) % N # 其中 N 为节点数。
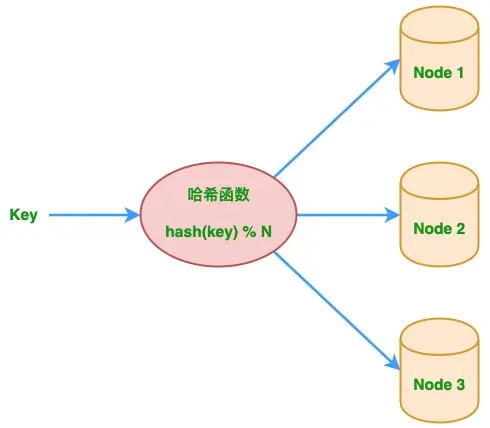
问题在于,当系统出现故障或是扩容导致集群节点数量N变化,映射规则的变化将造成分布式缓存系统之前的缓存失效,引发缓存雪崩
一致性hash算法
优点
- 可扩展:新增或删除节点,数据存储改动很小,不会影响系统
- 负载均衡:hash值平均分配到nodes
- 当部分虚拟节点含大量数据时,通过虚拟节点分裂,而不是重新hash,从而避免数据在虚拟节点分布不均衡
流程
- 将对象和虚拟服务器放到hash环
- 顺时针查找对象hash值距离最近的服务器,并让服务器缓存该对象
- 节点变化时,只有少部分对象需要重新分配服务器缓存
- 引入虚拟节点映射实际服务器,解决负载不均衡问题
缓存映射
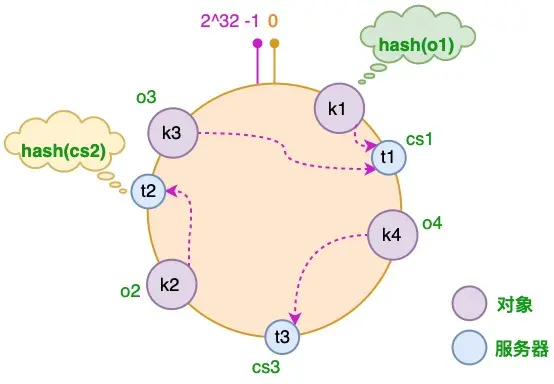
增加节点
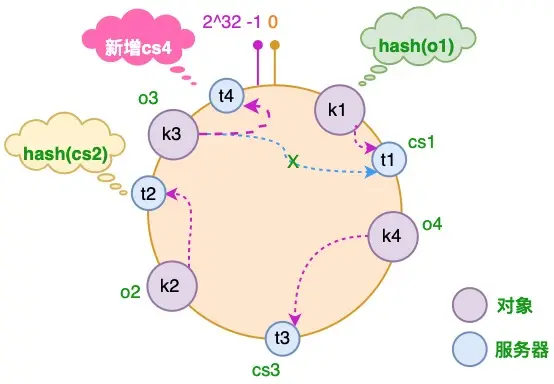
减少节点
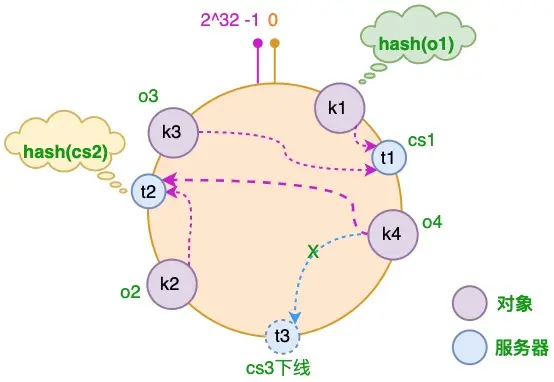
引入虚拟节点
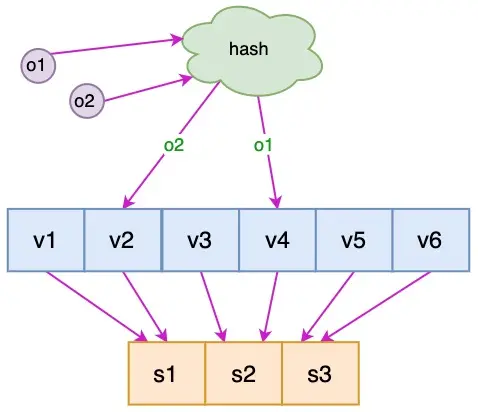
一致性hash实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
type Hash func(data []byte) uint32
type Map struct {
hash Hash
replicas int
keys []int
hashMap map[int]string
}
func New(replicas int, fn Hash) *Map {
m := &Map{
replicas: replicas,
hash: fn,
hashMap: make(map[int]string),
}
if m.hash == nil {
m.hash = crc32.ChecksumIEEE
}
return m
}
func (m *Map) Add(keys ...string) {
for _, key := range keys {
for i := 0; i < m.replicas; i++ {
hash := int(m.hash([]byte(strconv.Itoa(i) + key)))
m.keys = append(m.keys, hash)
m.hashMap[hash] = key
}
}
sort.Ints(m.keys)
}
func (m *Map) Get(key string) string {
if len(key) == 0 {
return ""
}
hash := int(m.hash([]byte(key)))
index := sort.Search(len(m.keys), func(i int) bool {
return m.keys[i] >= hash
})
return m.hashMap[m.keys[index%len(m.keys)]]
}
|
cover
id: 107066422
画师:异sj绘
